GPT-5.5 vs Claude Opus 4.7 코딩 성능 비교: 2026 최신 AI 모델 선택 가이드
2026년 4월, 단 7일 간격으로 Anthropic과 OpenAI가 각각 플래그십 모델을 출시하면서 AI 코딩 시장의 판이 완전히 새로 짜였습니다.
그런데 문제는 두 모델이 서로 다른 방향으로 진화했다는 점입니다. 어떤 모델이 더 좋다는 단순한 답은 없고, 어떤 작업에 어떤 모델이 맞는지를 아는 것이 실질적인 경쟁력이 됩니다.
두 모델의 공식 발표 자료와 독립 벤치마크를 직접 분석한 결과, 이 두 모델은 같은 링 위에서 싸우는 게 아니었습니다.
Claude Opus 4.7은 코드 정밀도와 검증 능력에서 강점을 보이고, GPT-5.5는 에이전틱 자율 실행과 장문 컨텍스트 처리에서 한 발 앞서 있습니다.
IT 개발자와 AI 도구 활용자로서 이 글을 끝까지 읽으면 여러분의 워크플로우에 맞는 모델을 명확하게 고를 수 있습니다.
지금부터 각 모델의 특징, 벤치마크 비교, 실전 선택 기준, 그리고 앞으로의 AI 방향까지 한 번에 정리해 드립니다.

Claude Opus 4.7 코딩 성능: 정밀도로 승부하는 Anthropic 최신 모델
Claude Opus 4.7 출시일·특징: 코딩 벤치마크 SWE-Bench Pro 64.3% 달성
Claude Opus 4.7은 2026년 4월 16일 Anthropic이 출시한 모델입니다. Opus 4.6 대비 가장 큰 변화는 고난도 소프트웨어 엔지니어링 작업에서의 정밀도 향상입니다.
단순히 코드를 빨리 생성하는 것이 아니라, 스스로 논리적 오류를 탐지하고 결과를 보고하기 전에 검증하는 방식으로 설계됐습니다.
실제로 Hex 팀의 93개 코딩 벤치마크에서 Opus 4.6 대비 해결률이 13% 향상됐으며, 이전 모델 두 개 모두 실패했던 4개 태스크를 추가로 해결했습니다.
“낮은 노력(low-effort) Opus 4.7이 중간 노력(medium-effort) Opus 4.6과 동등하다”는 평가가 나올 정도로 효율성 자체가 올라갔습니다.
Claude Opus 4.7 신기능 총정리: xhigh 에포트·Task Budget·고해상도 비전

xhigh 에포트 레벨 도입
기존 high와 max 사이에 새로운 xhigh 레벨이 추가됐습니다. Claude Code는 기본값으로 xhigh를 사용하도록 변경됐는데, 이는 코딩 작업에서 모델이 더 깊이 추론하도록 유도하는 설정입니다.
단순한 파라미터 추가가 아니라, 에이전틱 루프 전체에서 토큰 예산을 모델 스스로 인식하고 작업 범위를 조율하는 구조적 변화입니다.
Task Budget 제어
task-budgets-2026-03-13 헤더를 통해 에이전트 루프 전체의 토큰 예산을 지정할 수 있게 됐습니다.
max_tokens가 모델이 알 수 없는 하드 상한선이라면, task budget은 모델이 실시간으로 인식하면서 스스로 작업 범위를 조절하는 어드바이저리 예산입니다. 복잡한 멀티스텝 작업에서 특히 유용합니다.
고해상도 비전 지원
최대 3.75메가픽셀 이미지 처리를 지원하게 됐습니다. 이전 세대 대비 3배 이상의 해상도로, 코드 스크린샷, UI 목업, 기술 다이어그램 분석 정확도가 눈에 띄게 향상됐습니다.
사이버 보안 세이프가드
Anthropic의 Claude Mythos Preview 출시와 맞물려, Opus 4.7에는 금지된 사이버보안 용도를 자동 감지·차단하는 세이프가드가 내장됐습니다.
합법적인 보안 전문가를 위해서는 별도 Cyber Verification Program 참여 경로를 열었습니다.
Claude Opus 4.7 가격 및 API 접근성
가격은 Opus 4.6과 동일하게 유지됩니다. 입력 토큰 100만 개당 $5, 출력 토큰 100만 개당 $25입니다.
출시 첫날부터 Claude API, Amazon Bedrock, Google Cloud Vertex AI, Microsoft Foundry 전체에서 일반 제공(GA)됩니다.
GPT-5.5 코딩 성능: Codex 기반 자율 실행 AI의 실력은?
GPT-5.5 출시일·특징: 완전 재훈련 베이스 모델로 Terminal-Bench 82.7% 기록
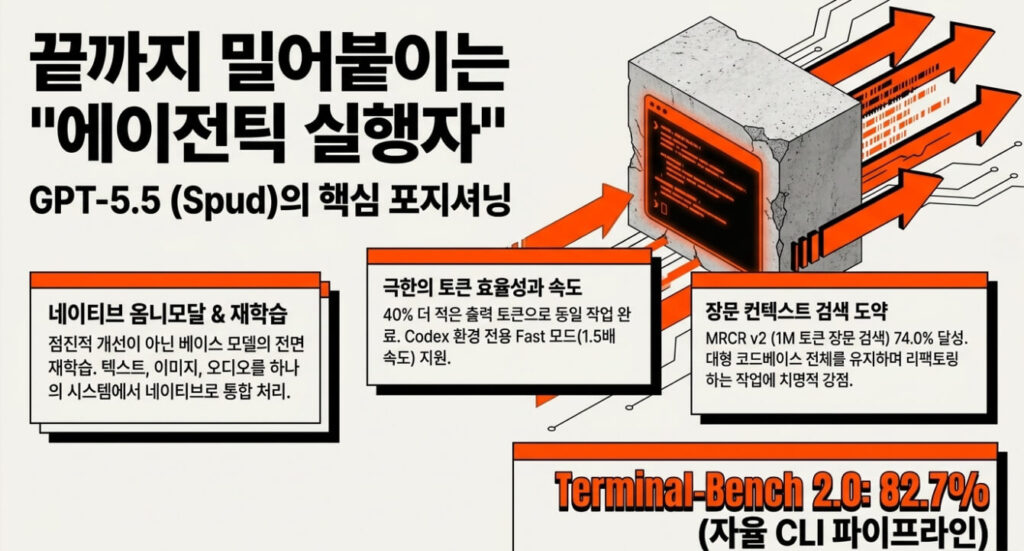
GPT-5.5(코드명 “Spud”)는 2026년 4월 23일 OpenAI가 출시한 모델입니다.
GPT-4.5 이후 처음으로 완전히 재훈련된 베이스 모델로, 기존 GPT-5.1~5.4가 점진적 개선이었다면 GPT-5.5는 아키텍처 수준에서의 새출발입니다.
핵심 포지셔닝은 “사람의 지속적인 개입 없이 계획, 실행, 검증, 반복을 수행하는 에이전틱 모델”입니다.
Codex 환경에서 동일한 작업을 약 40% 더 적은 출력 토큰으로 완료하는 효율성이 특히 주목받고 있습니다.
토큰당 가격은 2배 올랐지만, 실제 작업 단위 비용은 약 20% 증가에 그친다는 것이 OpenAI의 주장입니다.
GPT-5.5 주요 기능: 옴니모달·장문 컨텍스트·Codex Fast 모드 비교
네이티브 옴니모달 아키텍처
텍스트, 이미지, 오디오, 비디오를 하나의 통합 시스템에서 처리합니다.
이전 모델들이 각 모달리티를 별도 처리한 것과 달리, GPT-5.5는 멀티모달 정보를 통합적으로 이해하도록 설계됐습니다.
장문 컨텍스트 검색 성능 도약
MRCR v2(1M 토큰 장문 검색) 벤치마크에서 GPT-5.4의 36.6%에서 74.0%로 2배 이상 향상됐습니다.
Opus 4.7의 32.2%와 비교하면 42% 포인트 차이로, 이번 비교에서 가장 큰 단일 격차입니다.
대형 코드베이스나 장문 문서를 다루는 에이전트에게 결정적인 차이입니다.
Codex 통합 및 Fast 모드
Codex 환경에서는 일반 속도 외에 Fast 모드(1.5배 속도, 2.5배 비용) 옵션이 추가됐습니다.
긴급하게 반복 실행이 필요한 파이프라인에서 속도와 비용 사이를 조율할 수 있습니다.
GPT-5.5 가격 및 API 접근성
입력 토큰 100만 개당 $5, 출력 토큰 100만 개당 $30입니다.
ChatGPT Plus($20/월), Pro($200/월), Business, Enterprise 구독자에게 출시 당일 제공됐으며, API 롤아웃은 4월 24일부터 순차 진행 중입니다.
Codex의 경우 400K 컨텍스트 윈도우가 적용됩니다.
GPT-5.5 vs Claude Opus 4.7 벤치마크 비교: 코딩·에이전틱·추론 성능 수치 총정리
코딩 및 소프트웨어 엔지니어링 성능
| 벤치마크 | Claude Opus 4.7 | GPT-5.5 | 우위 |
|---|---|---|---|
| SWE-Bench Pro | 64.3% | 58.6% | Opus 4.7 ✅ |
| SWE-Bench Verified | 87.6% | – | Opus 4.7 ✅ |
| Terminal-Bench 2.0 | 69.4% | 82.7% | GPT-5.5 ✅ |
| Expert-SWE | – | 73.1% | GPT-5.5 ✅ |
에이전틱 및 도구 사용 성능
| 벤치마크 | Claude Opus 4.7 | GPT-5.5 | 우위 |
|---|---|---|---|
| MCP-Atlas 툴 오케스트레이션 | 79.1% | 75.3% | Opus 4.7 ✅ |
| OSWorld-Verified (컴퓨터 사용) | 78.0% | 78.7% | GPT-5.5 ✅ |
| BrowseComp | 79.3% | 90.1% (Pro) | GPT-5.5 ✅ |
추론 및 지식 성능
| 벤치마크 | Claude Opus 4.7 | GPT-5.5 | 우위 |
|---|---|---|---|
| GPQA Diamond | 93.6% | 94.5% | 사실상 동점 |
| MMLU 다국어 | 91.5% | 83.2% | Opus 4.7 ✅ |
| FrontierMath Tier 4 | 22.9% | 35.4% | GPT-5.5 ✅ |
| MRCR v2 (1M 장문 검색) | 32.2% | 74.0% | GPT-5.5 ✅ |
가격 및 스펙 비교
| 항목 | Claude Opus 4.7 | GPT-5.5 |
|---|---|---|
| 입력 토큰 (1M) | $5 | $5 |
| 출력 토큰 (1M) | $25 | $30 |
| 컨텍스트 윈도우 | 1M (API) | 1M (API) / 400K (Codex) |
| 클라우드 제공 | AWS·GCP·Azure·Foundry (즉시) | Codex·ChatGPT (즉시), API 순차 |
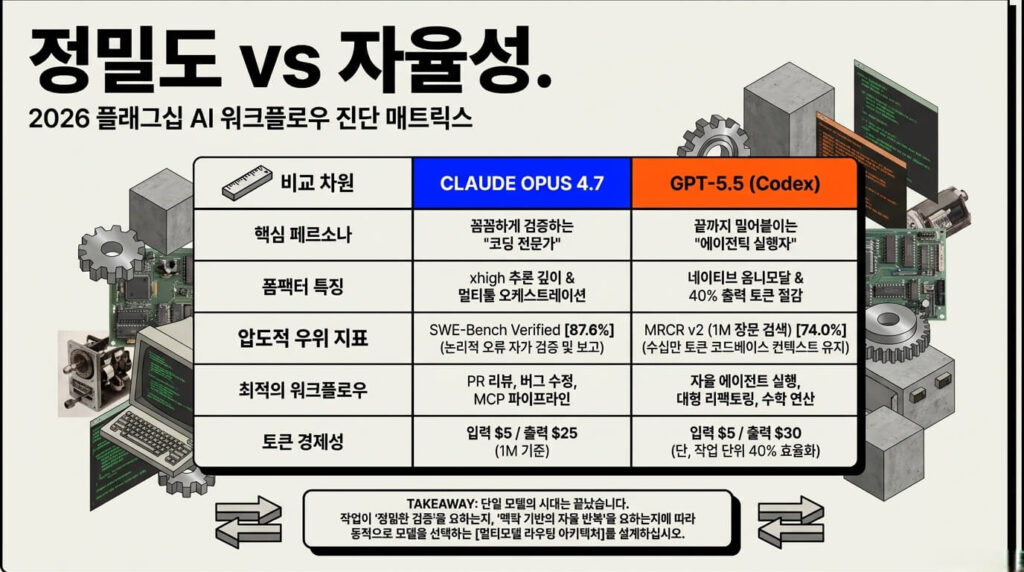
패턴 요약: Opus 4.7은 코드베이스 해결 정밀도와 MCP 툴 오케스트레이션에서 앞서고, GPT-5.5는 자율 실행 계획·장문 검색·수학 추론에서 강세입니다.
두 모델은 경쟁하는 축 자체가 다릅니다.
GPT-5.5 vs Claude Opus 4.7 선택 가이드: 내 작업에 맞는 AI 모델은?

Claude Opus 4.7 추천 상황: PR 리뷰·MCP 파이프라인·다국어 처리
PR 리뷰 및 코드베이스 리팩토링
SWE-Bench Pro 64.3%가 보여주듯, 기존 대형 코드베이스에서 버그를 찾고 수정하는 작업에서 Opus 4.7이 앞섭니다. 특히 논리적 오류를 스스로 검증하고 보고하는 방식은 사람의 리뷰 부담을 줄여줍니다.
MCP 기반 멀티툴 파이프라인
MCP-Atlas 79.1%로 GPT-5.5(75.3%)를 앞서는 Opus 4.7은 여러 툴을 정밀하게 오케스트레이션하는 에이전트 구조에 적합합니다. 툴 호출 순서와 결과 해석의 정확도가 중요한 워크플로우에서 선택하십시오.
다국어 처리 및 글로벌 서비스
MMLU 다국어 91.5%(GPT-5.5 대비 8.3%p 우위)는 한국어를 포함한 비영어권 서비스에서 실질적 차이를 만들 수 있습니다. 국제화(i18n) 작업, 다국어 고객 지원 에이전트 등에서 유리합니다.
기업 클라우드 기존 환경 활용
출시 첫날부터 AWS Bedrock, Google Vertex AI, Azure Foundry 모두에서 즉시 사용 가능합니다. 기존 클라우드 약정이 있는 기업이라면 추가 공급업체 계약 없이 바로 도입할 수 있습니다.
GPT-5.5 추천 상황: 자율 에이전트·대형 코드베이스·수학 연산
자율 에이전틱 코딩 파이프라인
Terminal-Bench 2.0 82.7%는 계획·실행·반복이 필요한 복잡한 CLI 워크플로우에서 GPT-5.5가 한 차원 높은 수준임을 보여줍니다. 사람의 개입을 최소화한 완전 자동화 파이프라인에 적합합니다.
대형 코드베이스 전체 탐색
MRCR v2 74.0%(Opus 4.7의 2배 이상)는 수십만 토큰 규모의 코드베이스나 문서를 전체 컨텍스트로 유지하며 작업하는 상황에서 결정적입니다. 레거시 코드 분석, 전체 저장소 단위 리팩토링에서 실질적 이점이 있습니다.
고급 수학·과학 연산
FrontierMath Tier 4에서 35.4%(Opus 4.7 22.9%)를 기록한 GPT-5.5는 복잡한 수학적 추론이 필요한 과학 계산, 금융 모델링, 데이터 과학 파이프라인에서 유리합니다.
ChatGPT / Codex 기존 구독 활용
이미 OpenAI 에코시스템을 사용 중이라면 추가 비용 없이 GPT-5.5를 즉시 활용할 수 있습니다. API 전환 없이 ChatGPT UI와 Codex에서 바로 접근 가능합니다.
2026년 하반기 AI 코딩 모델 전망: GPT-5.5·Claude Opus 4.7 이후는?
AI 모델 릴리즈 전쟁·에이전틱 AI 표준화·보안 인증 체계 부상
릴리즈 속도 자체가 경쟁 전략이 됐습니다
GPT-5.4 출시(3월 5일)에서 GPT-5.5(4월 23일)까지 불과 7주입니다. Anthropic도 Opus 4.6에서 Opus 4.7까지의 사이클이 빨라지고 있습니다.
릴리즈 케이던스 자체가 경쟁 우위가 된 상황으로, 2026년 하반기에는 현재의 플래그십 모델이 2~3개 세대 이상 업데이트될 가능성이 높습니다.
컨텍스트 윈도우 우위는 사라졌습니다
두 모델 모두 1M 토큰 컨텍스트를 지원합니다. 이제 차별화 요소는 컨텍스트 크기가 아니라 그 안에서 얼마나 정확하게 검색하고 추론하느냐입니다.
GPT-5.5의 MRCR v2 도약이 보여주듯, 장문 컨텍스트 품질이 다음 경쟁 축이 될 것입니다.
에이전틱 AI가 기본값이 됩니다
두 회사 모두 단일 쿼리-응답 모델이 아닌 멀티스텝 자율 실행 에이전트로 플래그십을 포지셔닝하고 있습니다.
2026년 하반기에는 에이전틱 성능이 플래그십의 필수 조건이 되고, 단순 QA 성능은 중간 티어 모델의 영역으로 내려갈 것으로 예측됩니다.
사이버 보안 역량이 차세대 차별점으로 부상합니다
Anthropic의 Mythos Preview가 보안 우려로 일반 공개를 보류한 사례는, 최상위 AI 역량이 사이버 보안에서 양날의 검임을 공식화했습니다.
Opus 4.7의 Cyber Verification Program은 이 딜레마를 제도적으로 풀려는 첫 시도입니다. 향후 모델들은 보안 용도 별도 인증 체계를 갖추는 방향으로 진화할 가능성이 큽니다.
2026 AI 모델 선택 전략: 멀티모델 아키텍처가 정답인 이유
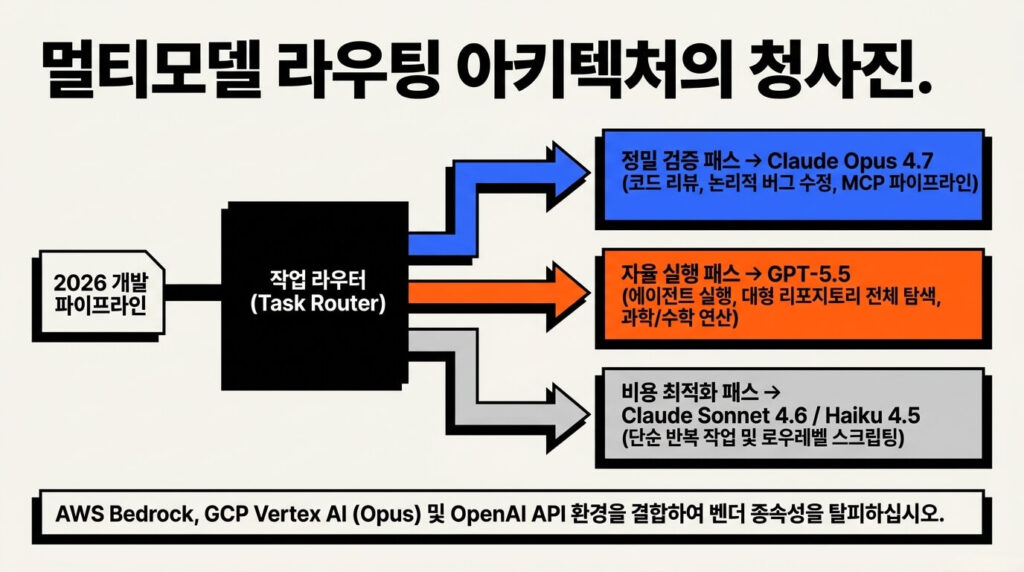
2026년 현재 단 하나의 모델에 올인하는 전략은 비효율적입니다.
라우팅 레이어를 구성해 작업 유형에 따라 모델을 동적으로 선택하는 멀티모델 아키텍처가 현실적인 정답입니다.
추천 구성은 다음과 같습니다.
- 코드 리뷰·버그 수정·MCP 파이프라인 → Claude Opus 4.7
- 자율 에이전트 실행·대형 코드베이스 탐색·수학 추론 → GPT-5.5
- 비용 최적화가 필요한 반복 작업 → Claude Sonnet 4.6 또는 Haiku 4.5
가장 중요한 제언은 직접 테스트입니다. 벤치마크는 방향을 알려주지만, 여러분의 실제 코드베이스와 작업 패턴에서 어떤 모델이 더 나은지는 직접 비교해야 알 수 있습니다.
두 모델 모두 API 접근이 가능한 지금, 같은 작업을 두 모델에게 시켜보는 것이 가장 빠른 결론입니다.
맺음말
2026년 4월은 AI 모델 경쟁 역사에서 가장 치열한 한 주로 기록될 것입니다.
Claude Opus 4.7과 GPT-5.5는 각각 “정밀하게 검증하는 코딩 전문가” 와 “끝까지 밀어붙이는 에이전틱 실행자” 로 포지셔닝이 갈렸습니다.
어느 쪽이 절대적으로 우월하다는 결론은 없습니다. 여러분의 작업 방식, 기존 클라우드 환경, 비용 구조에 따라 최적 선택이 달라집니다.
앞으로도 이런 AI 모델 심층 비교와 실전 활용 가이드를 계속 발행할 예정입니다.
FAQ: GPT-5.5 vs Claude Opus 4.7 코딩 성능 자주 묻는 질문
Q1. GPT-5.5와 Claude Opus 4.7 중 코딩에는 어떤 모델이 더 좋습니까?
A. 코드 정밀도와 버그 수정은 Opus 4.7(SWE-Bench Pro 64.3%), 자율 실행 에이전트 코딩은 GPT-5.5(Terminal-Bench 2.0 82.7%)가 앞섭니다.
Q2. GPT-5.5 가격이 2배 올랐는데 실제 비용 부담도 2배입니까?
A. 아닙니다. GPT-5.5는 동일 작업을 40% 적은 토큰으로 처리해, 실제 작업 단위 비용 증가는 약 20% 수준입니다.
Q3. Claude Opus 4.7의 xhigh 에포트 레벨은 무엇입니까?
A. 기존 high와 max 사이에 추가된 추론 깊이 설정으로, Claude Code의 기본값이 됐으며 복잡한 코딩 작업에서 정확도를 높입니다.
Q4. GPT-5.5와 Claude Opus 4.7 모두 1M 토큰 컨텍스트를 지원합니까?
A. API 기준으로는 두 모델 모두 1M 토큰을 지원합니다. 단, GPT-5.5 Codex는 현재 400K 컨텍스트로 제한됩니다.
Q5. 한국어 처리 성능은 GPT-5.5와 Claude Opus 4.7 중 어느 모델이 더 낫습니까?
A. MMLU 다국어 벤치마크에서 Opus 4.7이 91.5%로 GPT-5.5(83.2%)를 8.3%p 앞서, 다국어 작업에서는 Opus 4.7이 유리합니다.
Q6. AWS나 GCP를 이미 쓰고 있다면 어떤 AI 모델이 편합니까?
A. Claude Opus 4.7이 출시 첫날부터 Amazon Bedrock과 Google Vertex AI에서 즉시 사용 가능해 기존 클라우드 환경에서 바로 활용할 수 있습니다.
Q7. GPT-5.5와 Claude Opus 4.7을 동시에 쓰는 멀티모델 전략이 가능합니까?
A. 가능합니다. 작업 유형별로 모델을 라우팅하는 멀티모델 아키텍처가 2026년 현재 가장 효율적인 전략으로 권장됩니다.
관련 인기 글 모음



 모델 개념과 활용사례")















